Back to Reviews
ICCV 2023: Selected Posters
Vision-Language Models
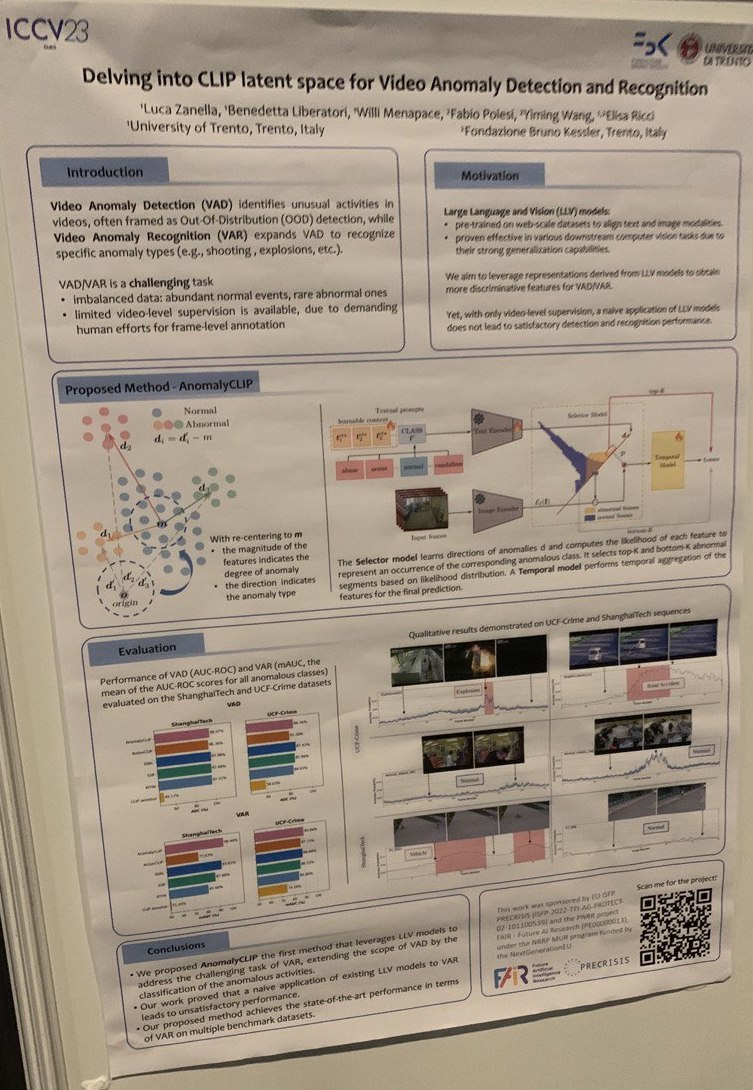
- Delving into CLIP latent space for Video Anomaly Detection and Recognition
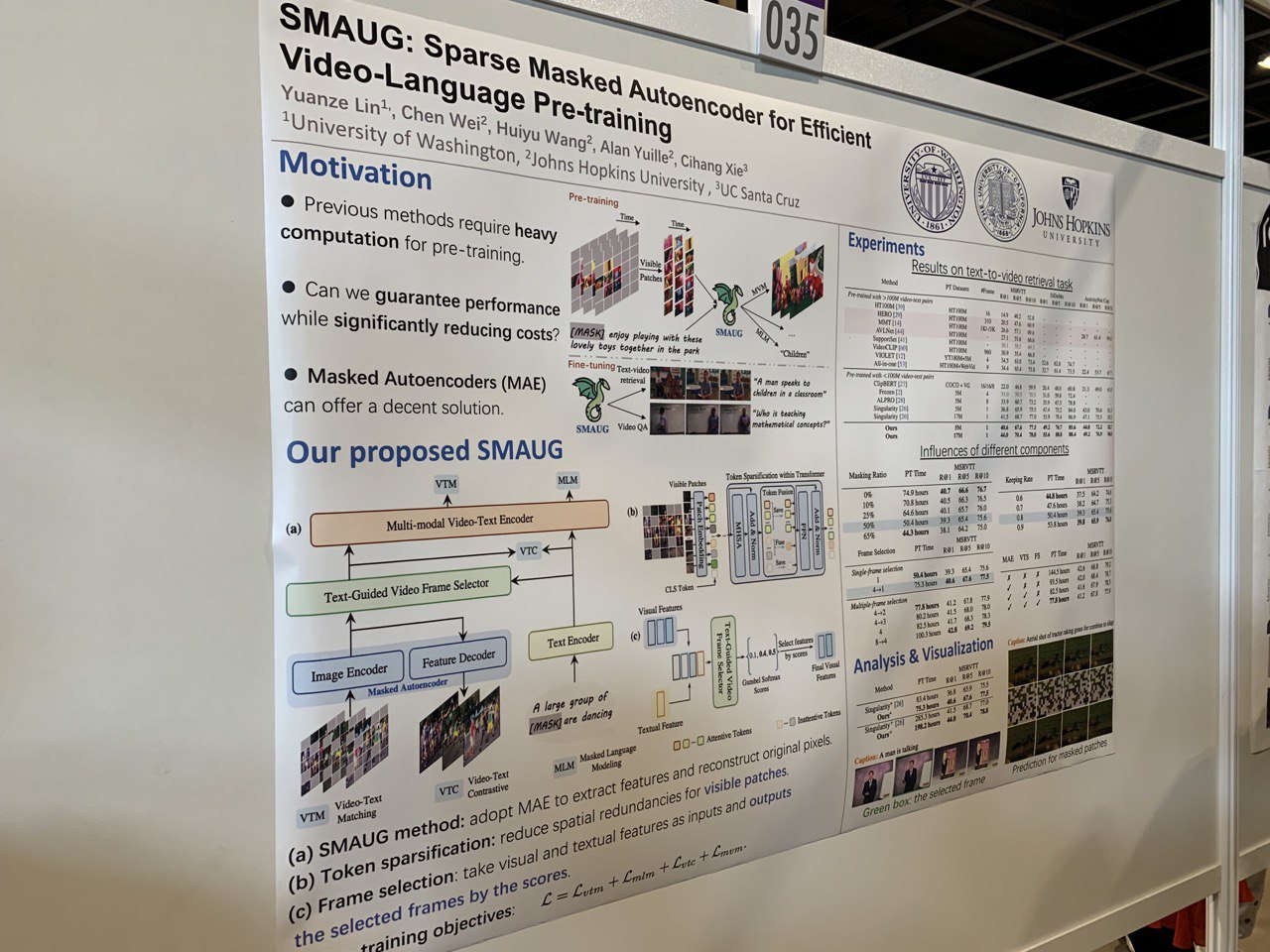
- SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
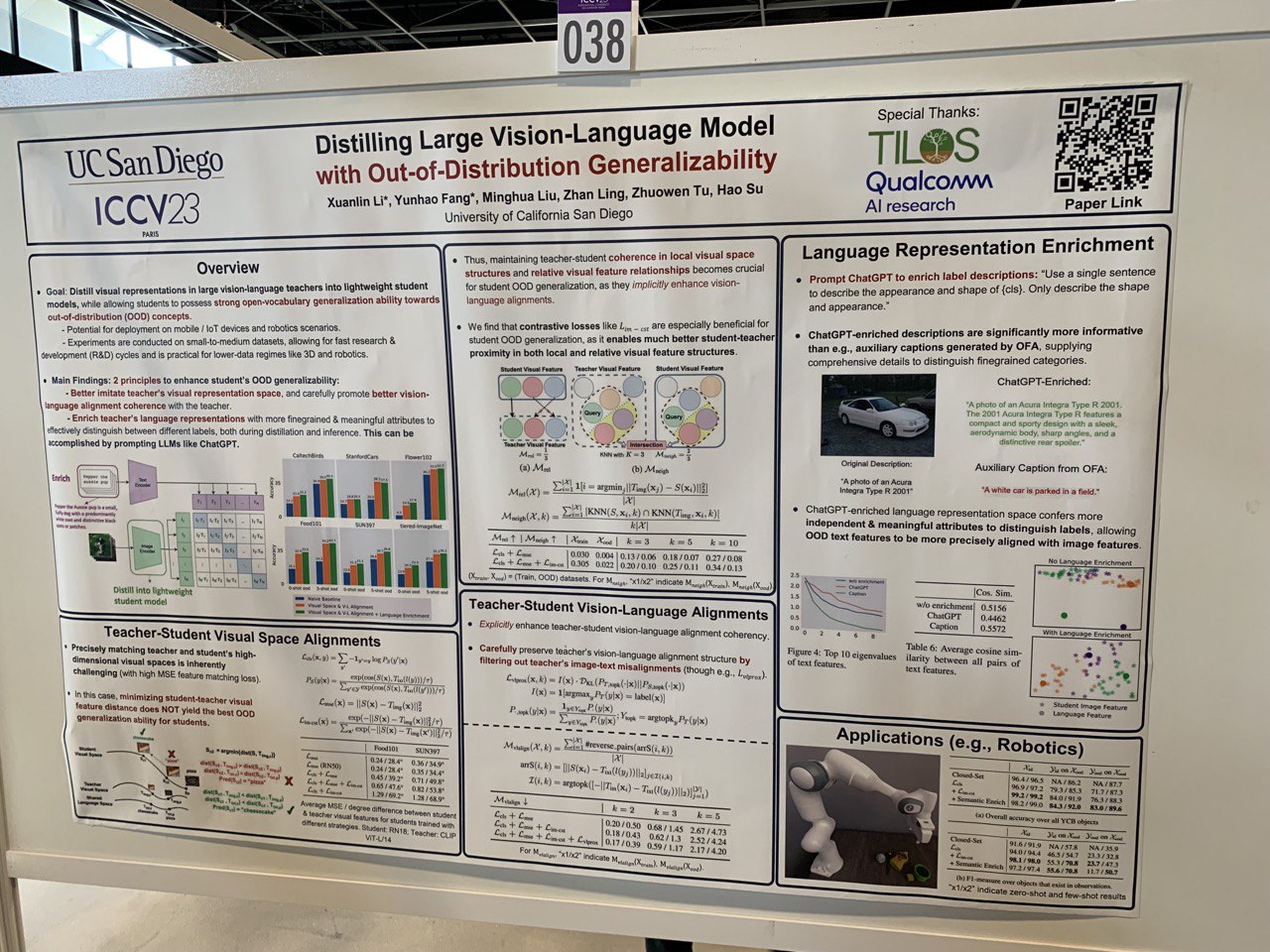
- Distilling Large Vision-Language Model with Out-of-Distribution Generalizability
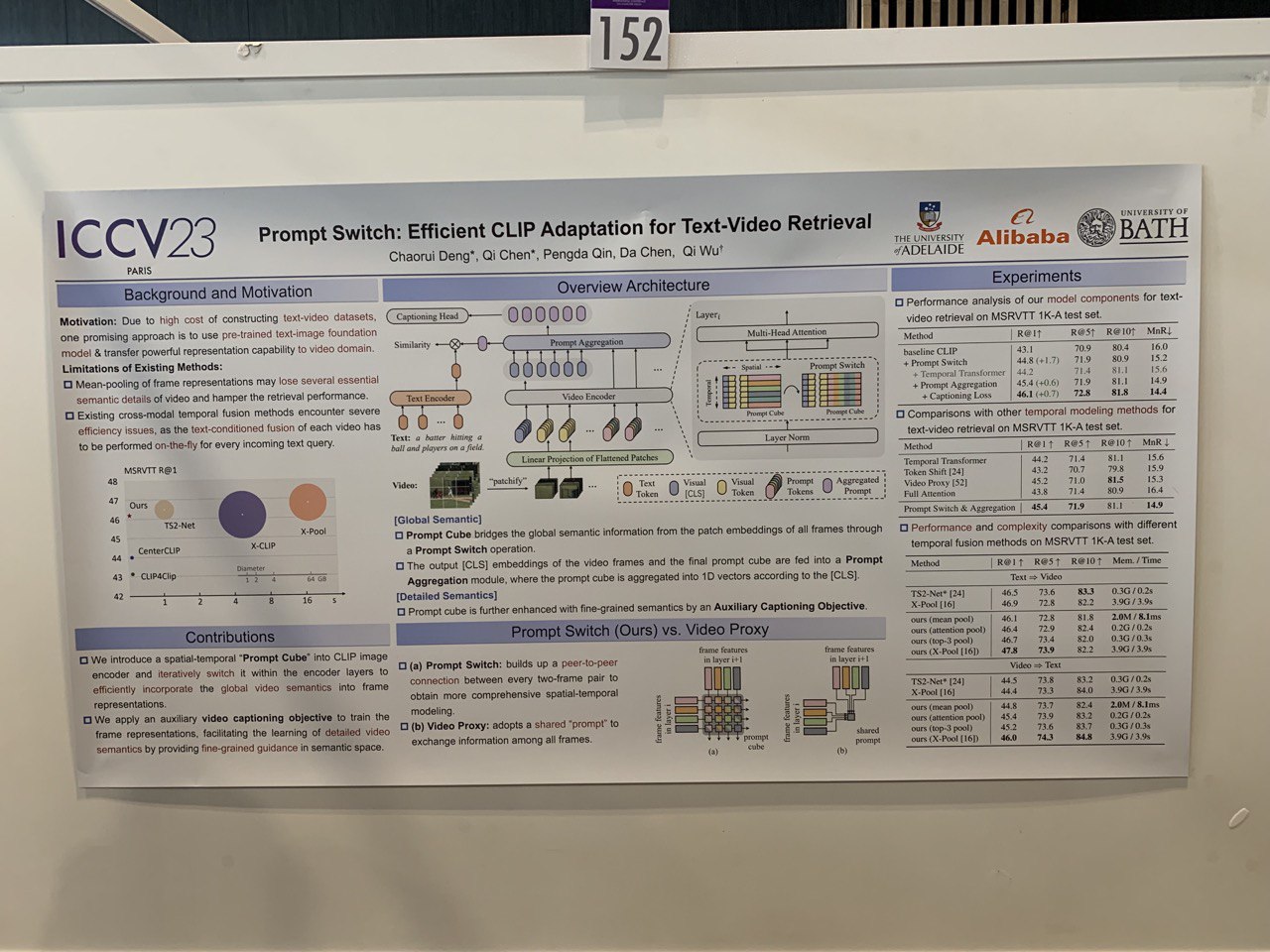
- Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
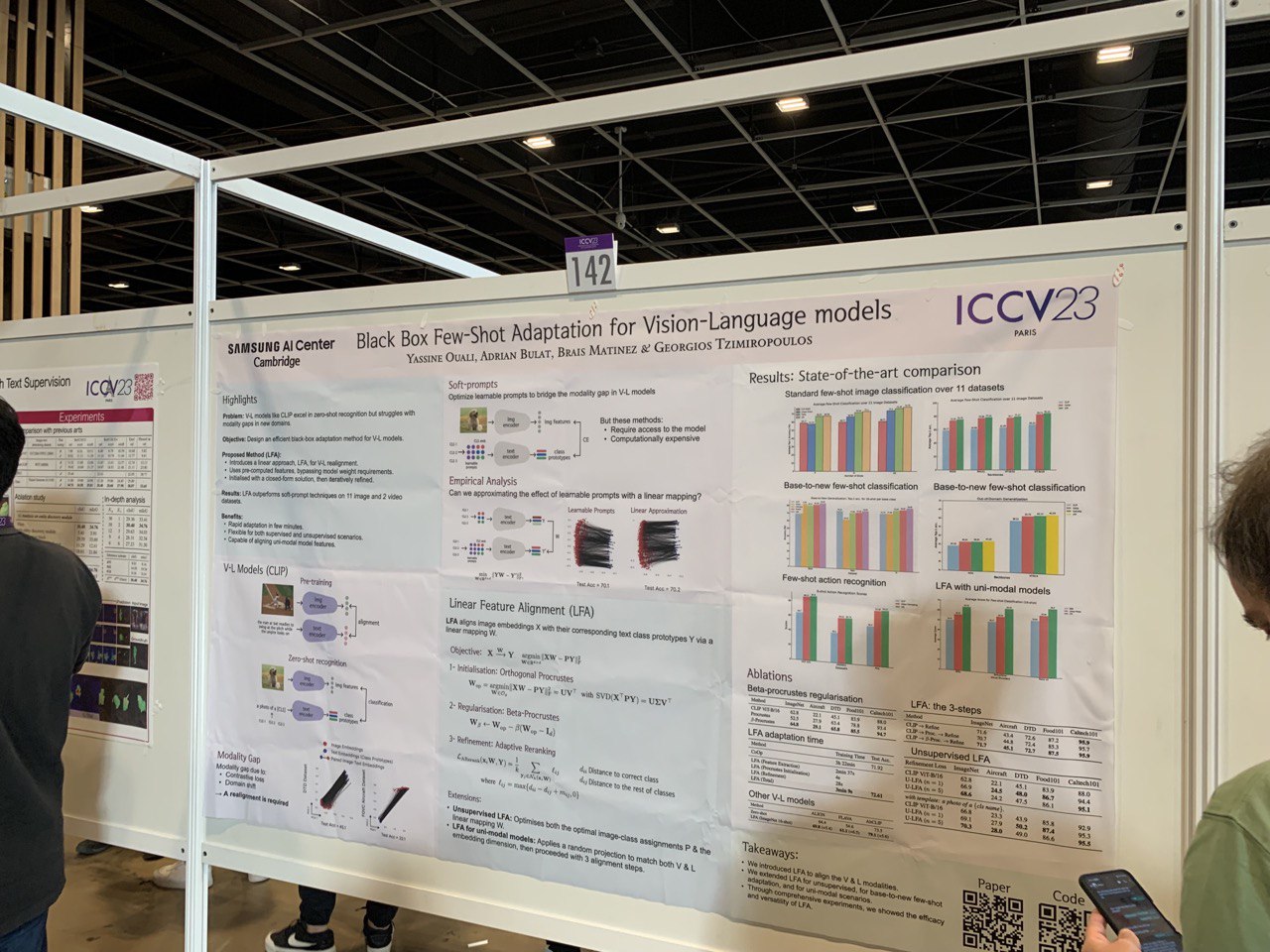
- Black Box Few-Shot Adaptation for Vision-Language Models
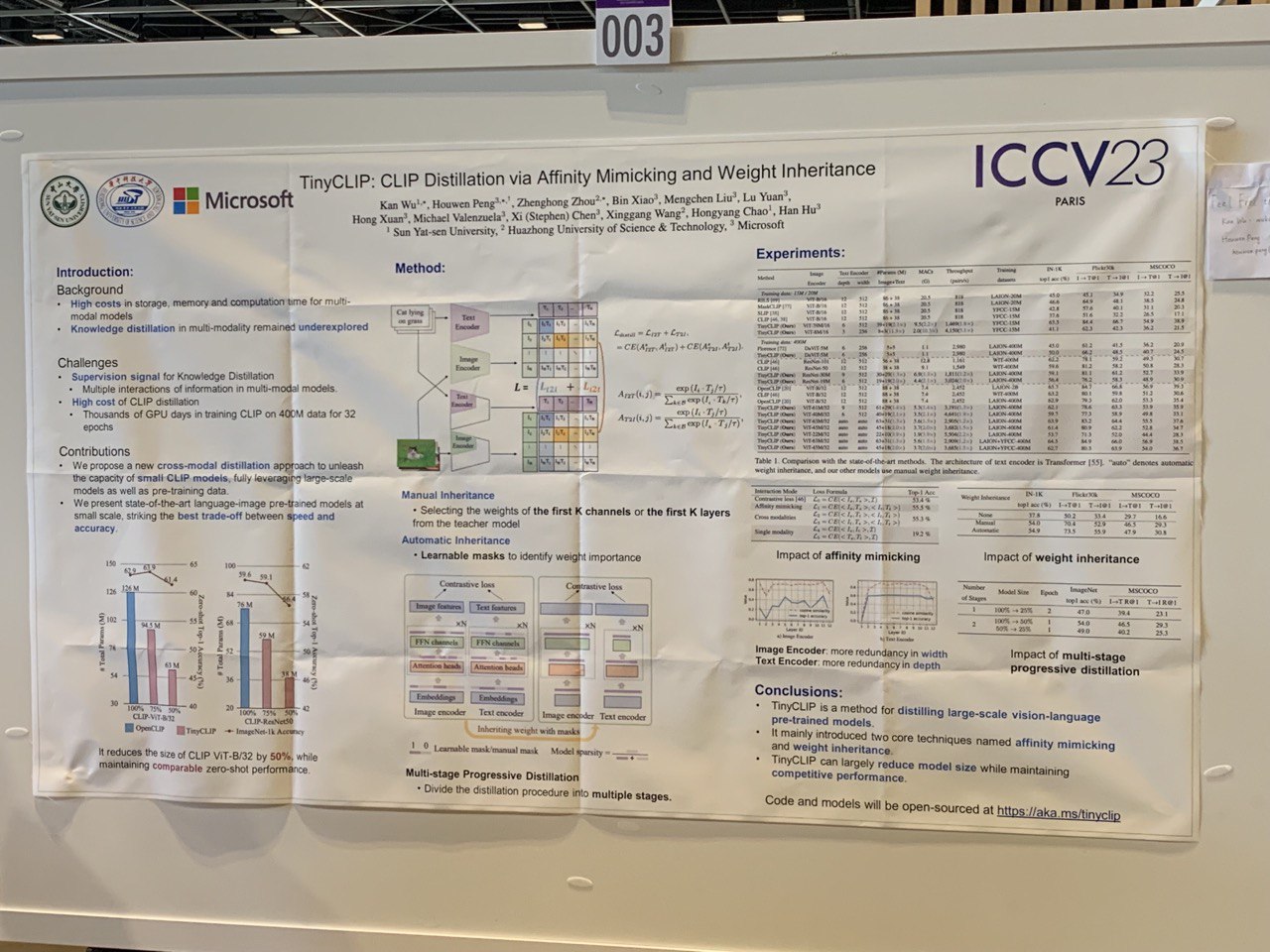
- TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
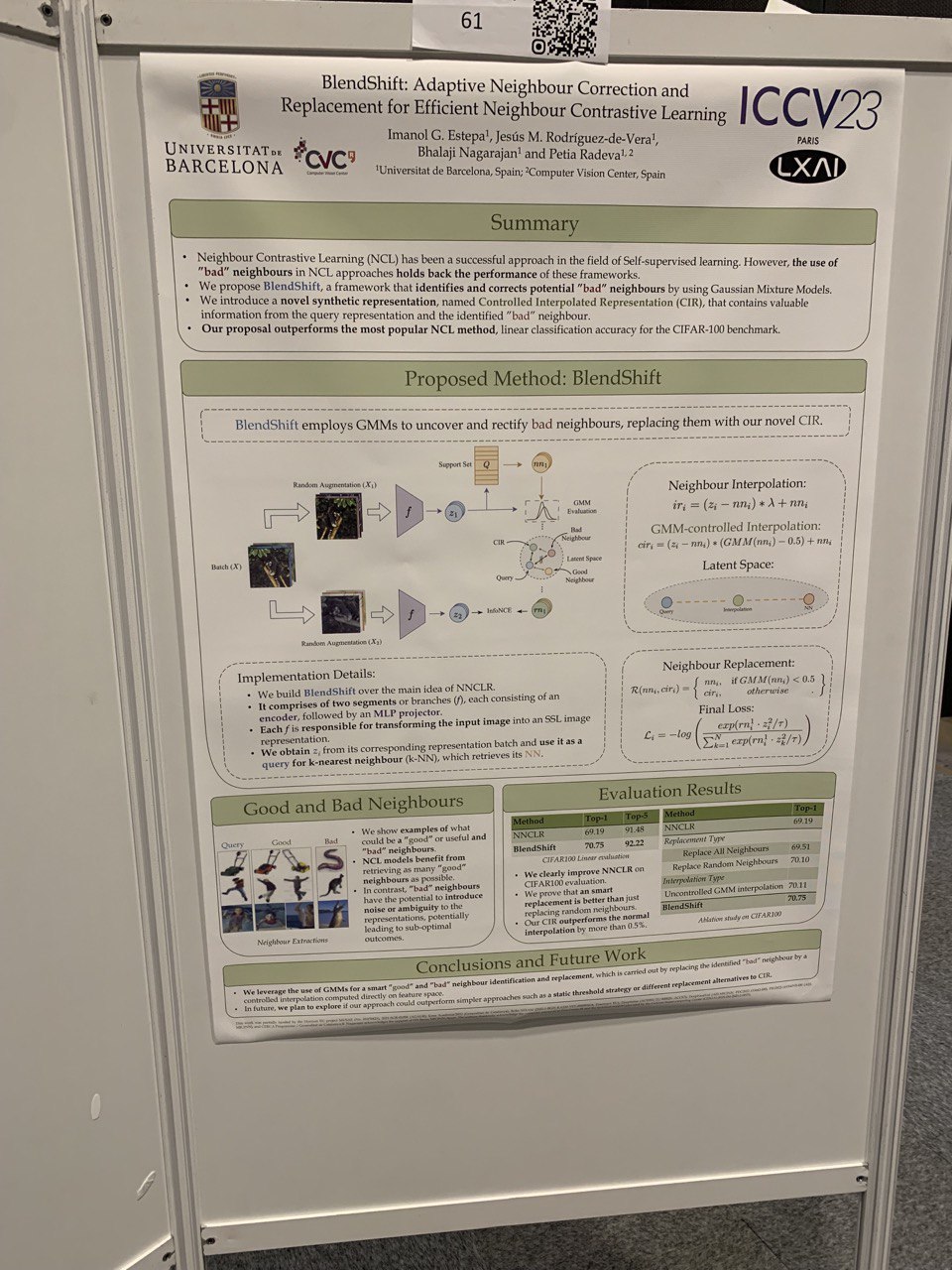
- BlendShift: Adaptive Neighbour Correction and Replacement for Efficient Neighbour Contrastive Learning
Vision Models
- SeiT: Storage-Efficient Vision Training with Tokens Using 1% of Pixel Storage
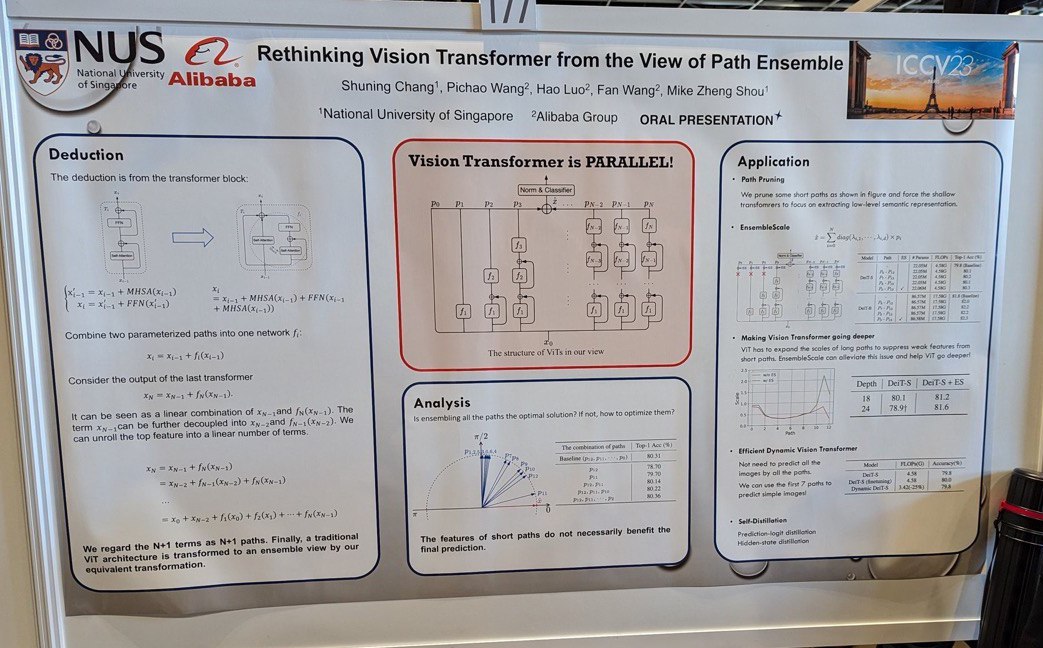
- Rethinking Vision Transformer from the View of Path Ensemble
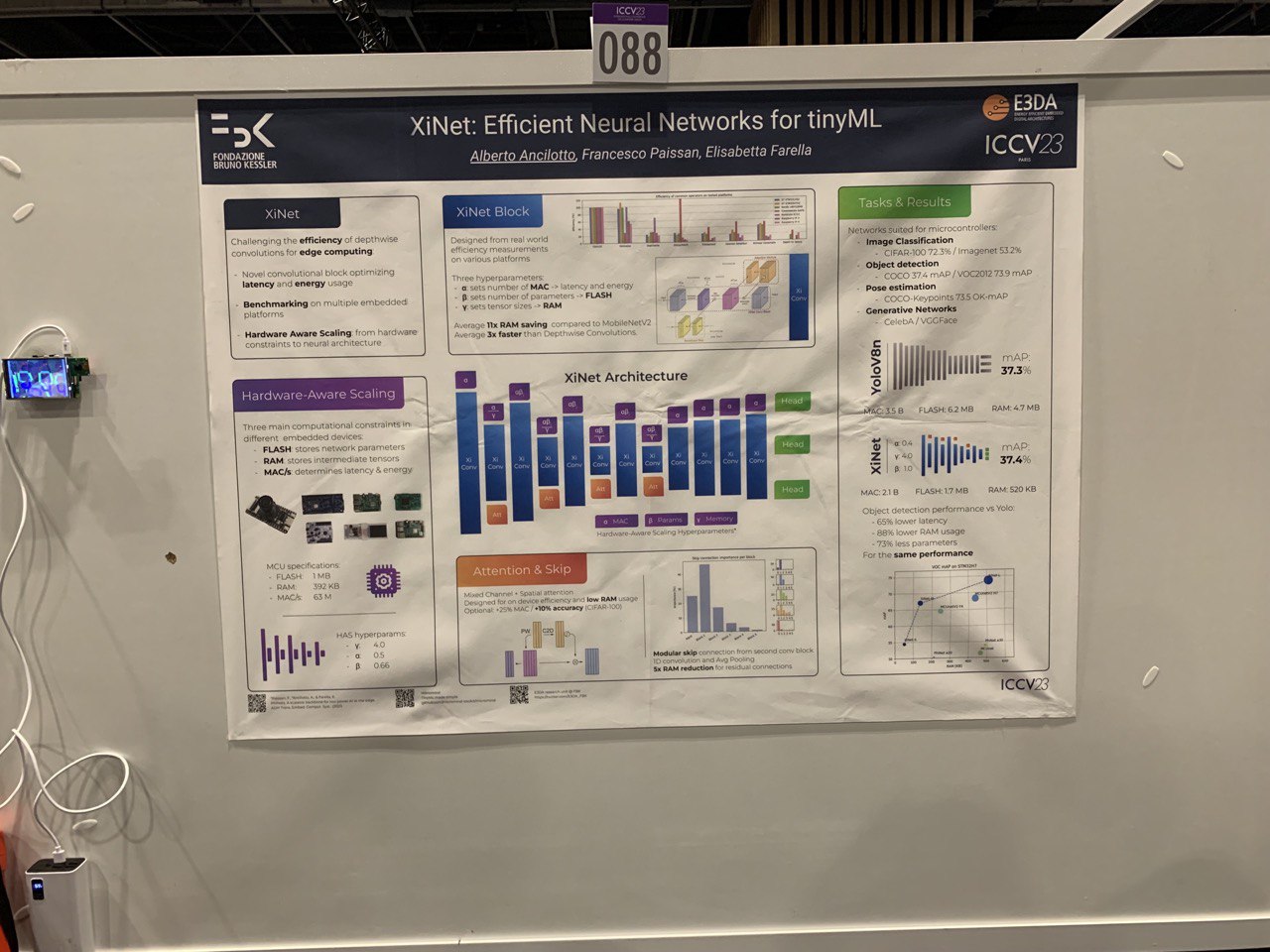
- XiNet: Efficient Neural Networks for tinyML
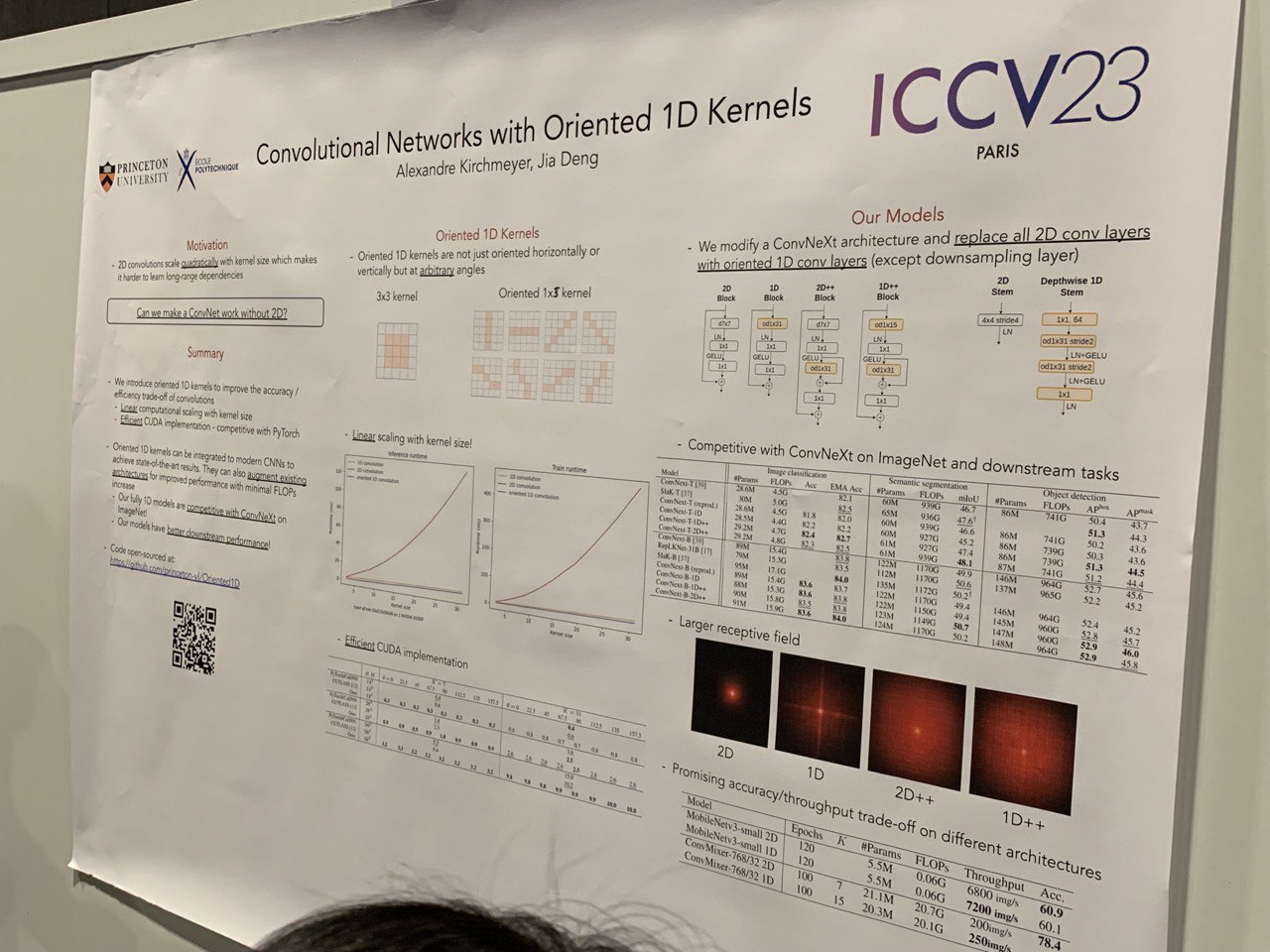
- Convolutional Networks with Oriented 1D Kernels
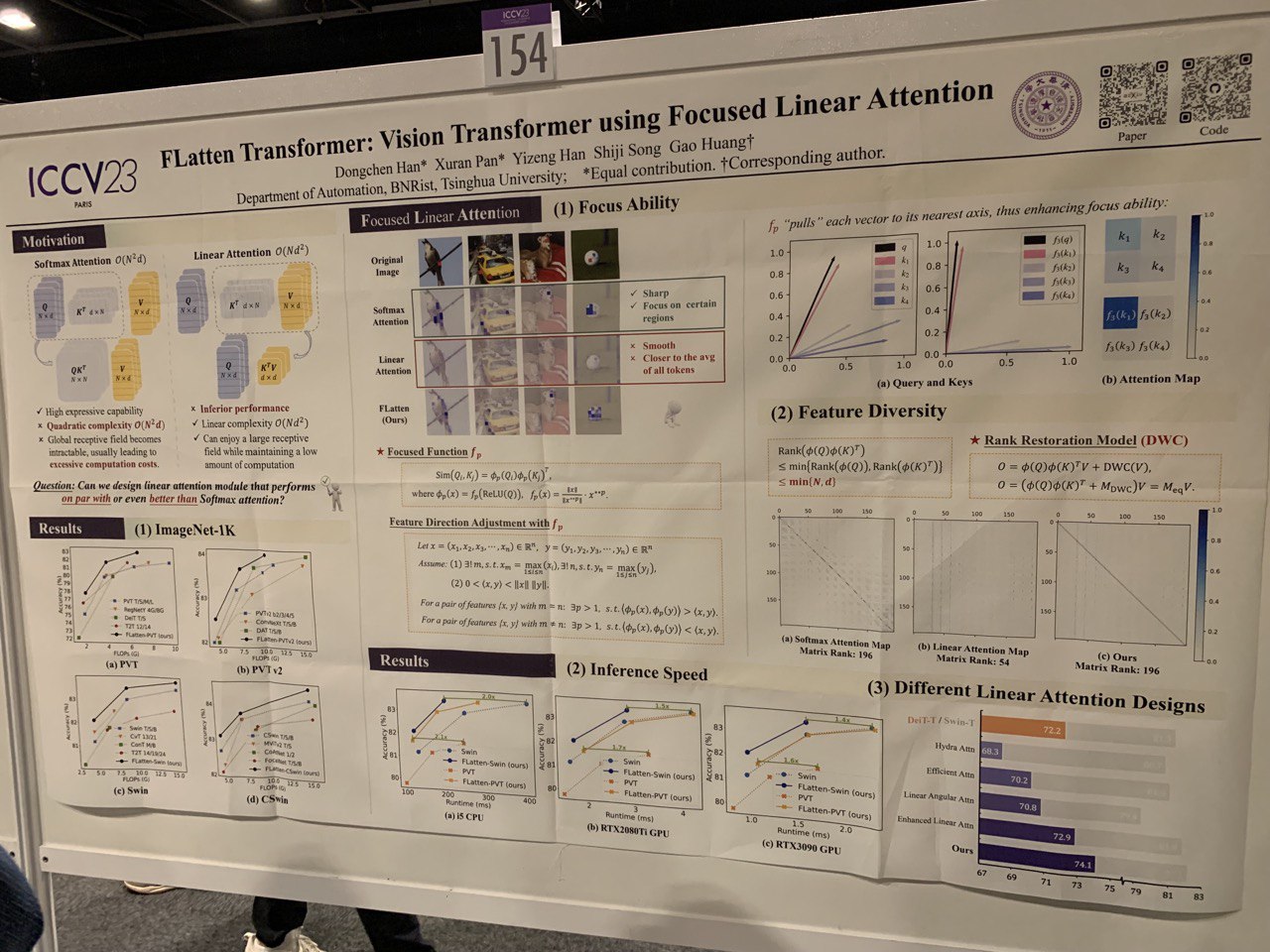
- FLatten Transformer: Vision Transformer using Focused Linear Attention
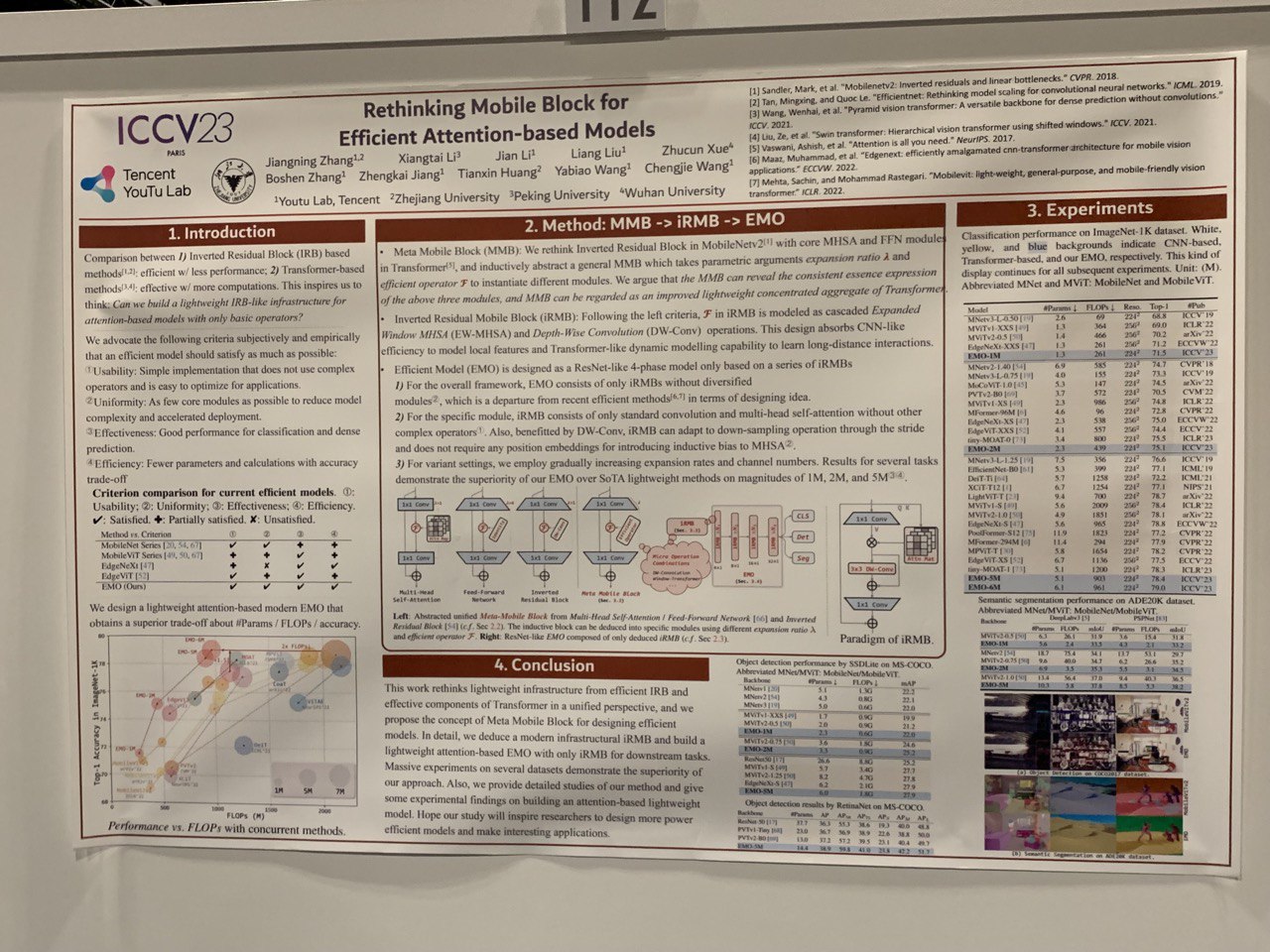
- Rethinking Mobile Block for Efficient Attention-based Models
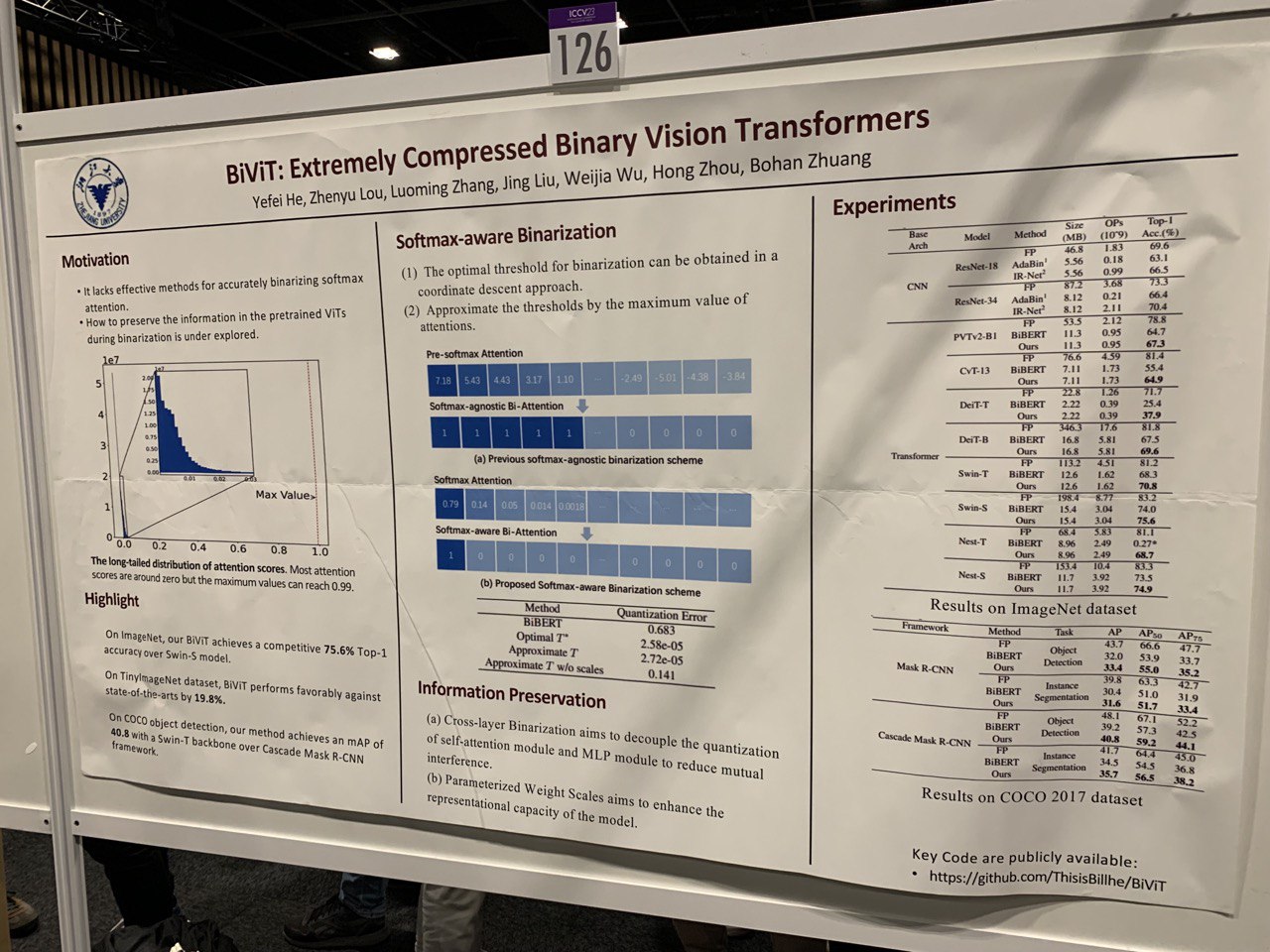
- BiViT: Extremely Compressed Binary Vision Transformers

Egocentric
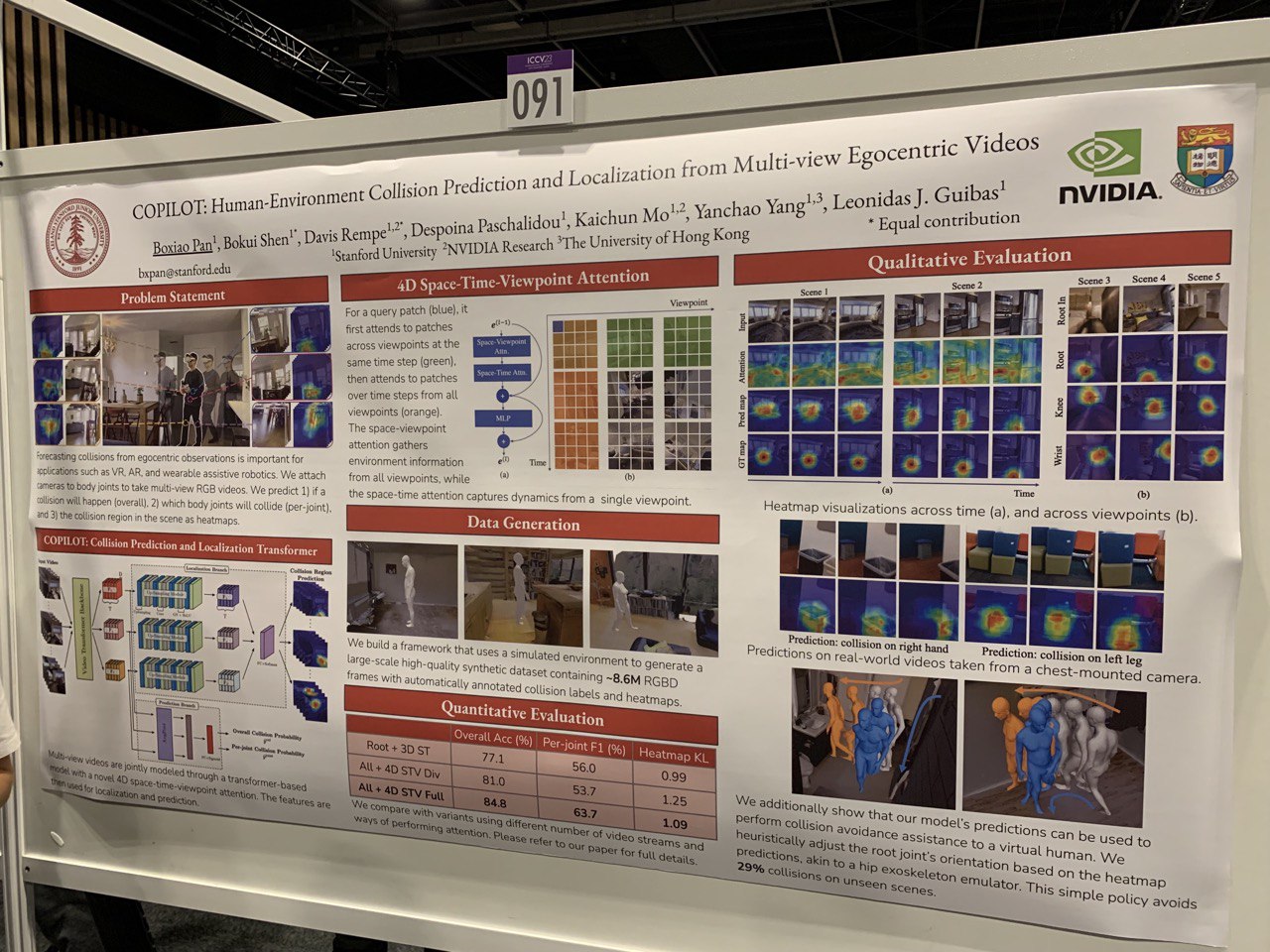
- COPliOT: Human-Environment Collision Prediction and Localization from Multi-view Egocentric Videos
- EGO-ONLY: EGOCENTRIC ACTION DETECTION WITHOUT EXOCENTRIC TRANSFERRING

Video
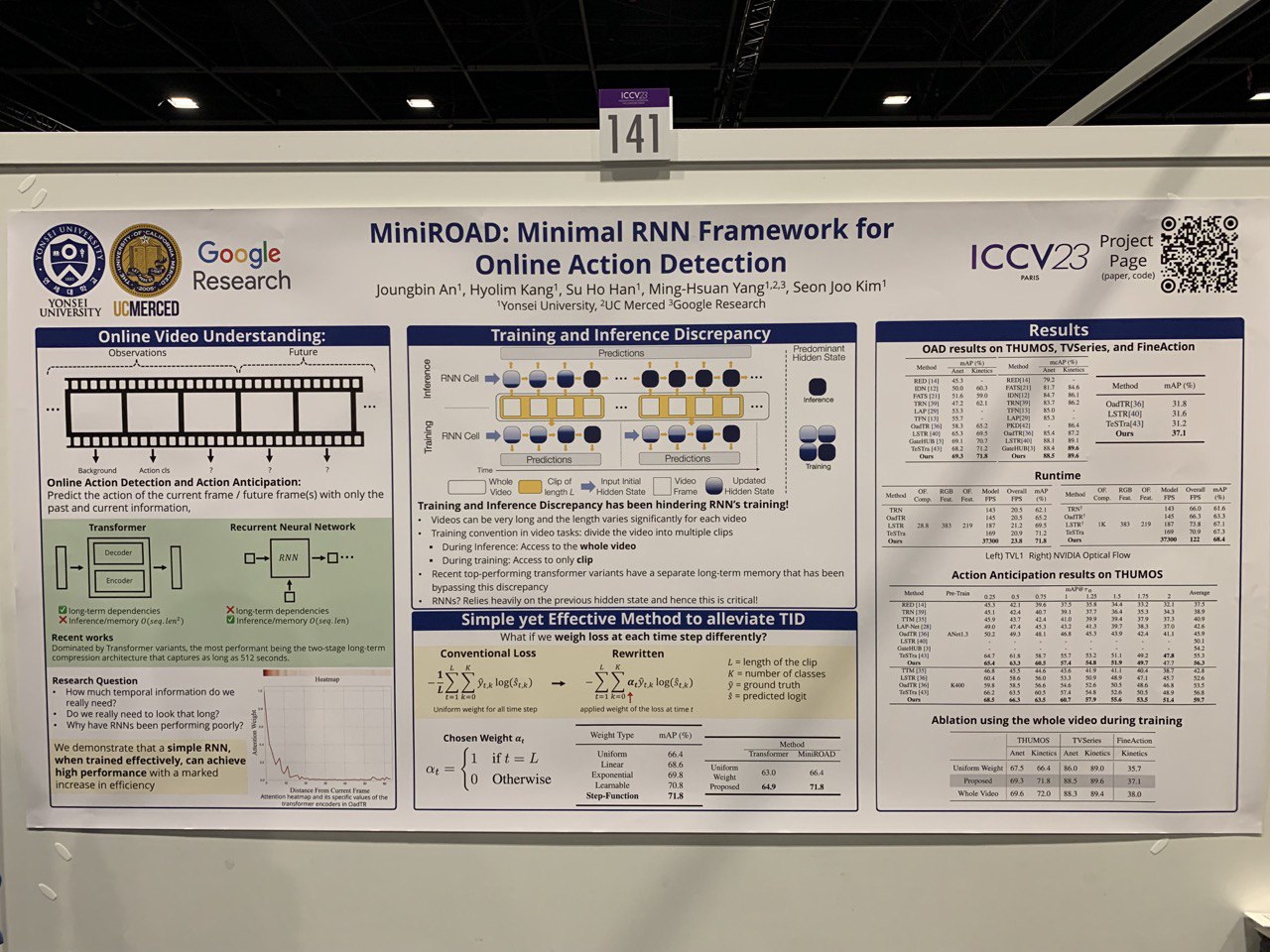
- MiniROAD: Minimal RNN Framework for Online Action Detection
- Spatio-temporal Prompting Network for Robust Video Feature Extraction
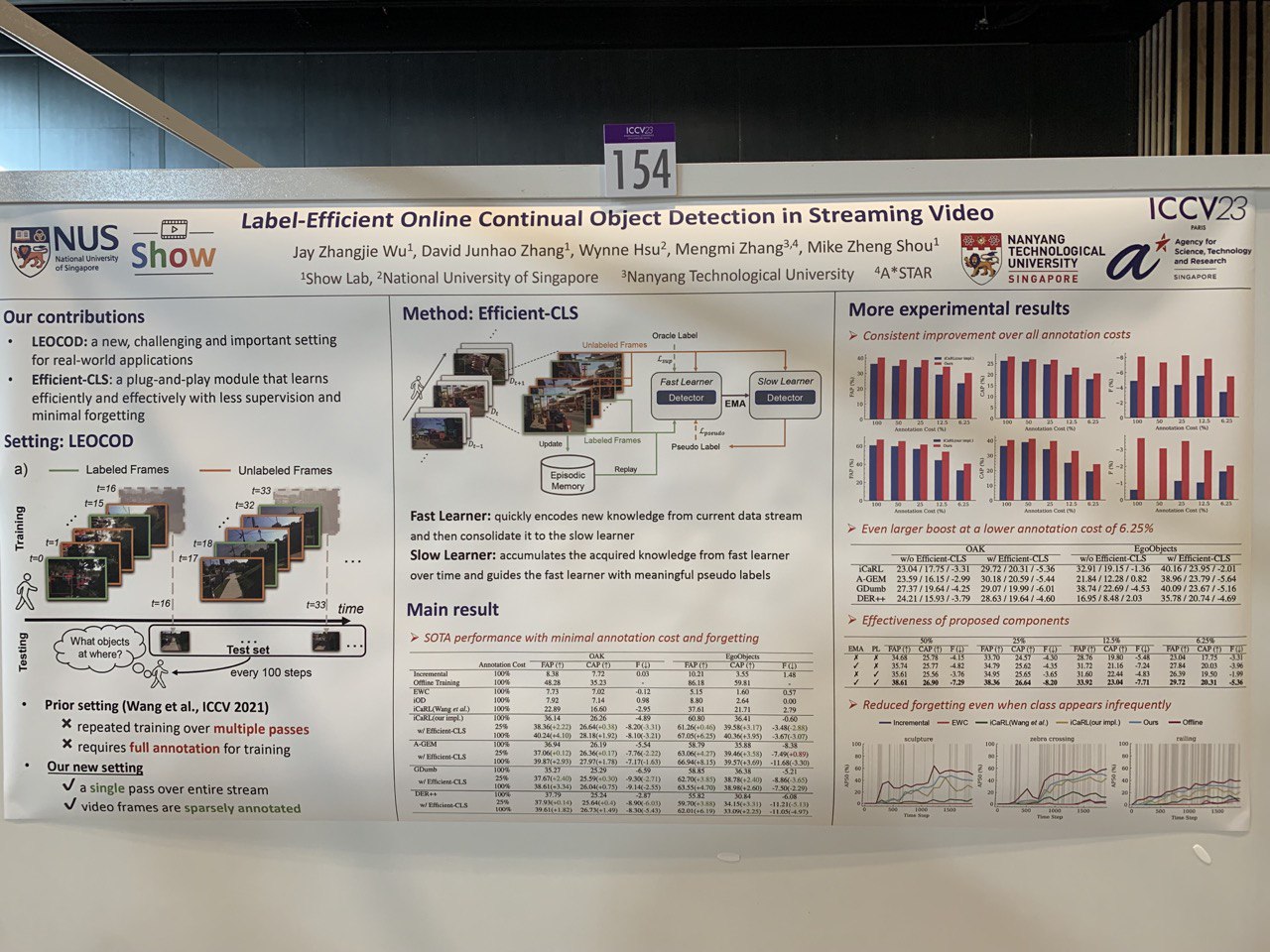
- Label-Efficient Online Continual Object Detection in Streaming Video
- Efficient Video Prediction via Sparsely Conditioned Flow Matching

Anonymization
- PRIFACE: A Novel Pipeline for Enhancing and Evaluating Face Anonymization
