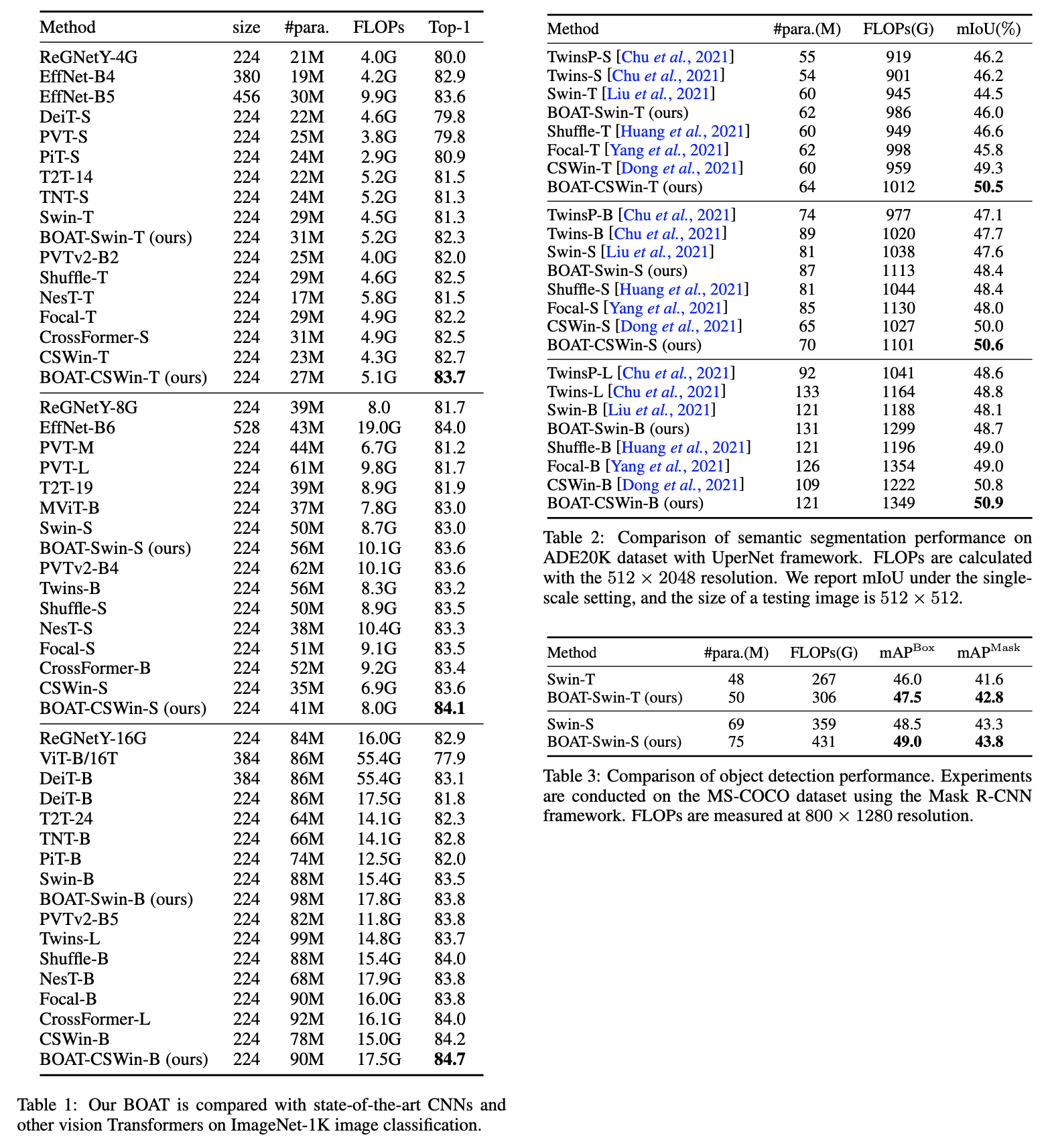
BOAT: Bilateral Local Attention Vision Transformer
Modification of Vision Transformer that makes use of grouped patches that share similarities in feature space.
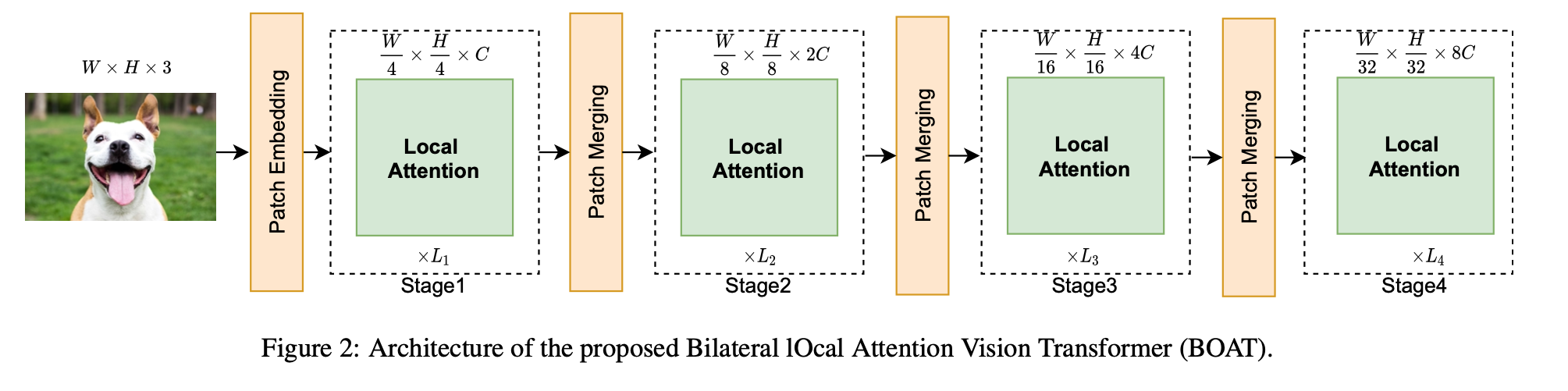
Bilateral Local Attention Block
Image-space Local Attention (ISLA), or ISLA for short, computes self-attention among tokens from the same local window. Patches within the same local window are likely to be closely related to each other.
To make use of information dropped by ISLA, Feature-Space Local Attention (FSLA) is introduced. Token features are grouped using balanced hierarchical clustering, and FSLA computes self-attention among tokens that are close in feature space.
Experiments
Slightly increased number of parameters leads to accuracy improvements of SWIN and CSWin models for main computer vision tasks (classification, segmentation, object detection).
The neural network is composed of 3 hidden layers. The first layer has 32 neurons, while the second layer has 8, the third layer has 4 neurons. Such simple models can be efficiently trained using SGD and they are not so susceptible to overfitting.